

代码拉取完成,页面将自动刷新
同步操作将从 zieckey/evpp 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
The throughput benchmark test of evpp against Boost.Asio
Boost.Asio is a cross-platform C++ library for network and low-level I/O programming that provides developers with a consistent asynchronous model using a modern C++ approach.
We use the test method described at http://think-async.com/Asio/LinuxPerformanceImprovements using ping-pong protocol to do the throughput benchmark.
Simply to explains that the ping pong protocol is the client and the server both implements the echo protocol. When the TCP connection is established, the client sends some data to the server, the server echoes the data, and then the client echoes to the server again and again. The data will be the same as the table tennis in the client and the server back and forth between the transfer until one side disconnects. This is a common way to test throughput.
The test code of evpp is at the source code benchmark/throughput/evpp, and at here https://github.com/Qihoo360/evpp/tree/master/benchmark/throughput/evpp. We use tools/benchmark-build.sh to compile it. The test script are single_thread.sh and multiple_thread.sh.
The test code of asio is at https://github.com/huyuguang/asio_benchmark using commits 21fc1357d59644400e72a164627c1be5327fbe3d and the client2.cpp/server2.cpp test code. The test script is single_thread.sh and multiple_thread.sh.
We have done two benchmarks:
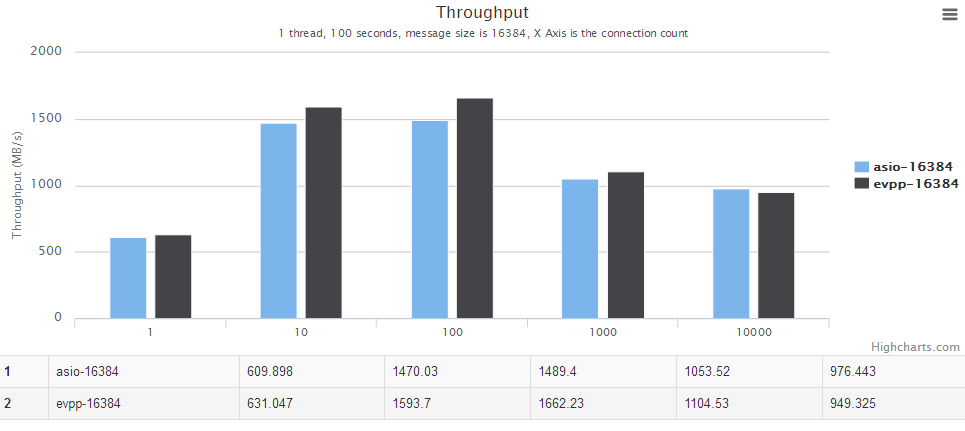
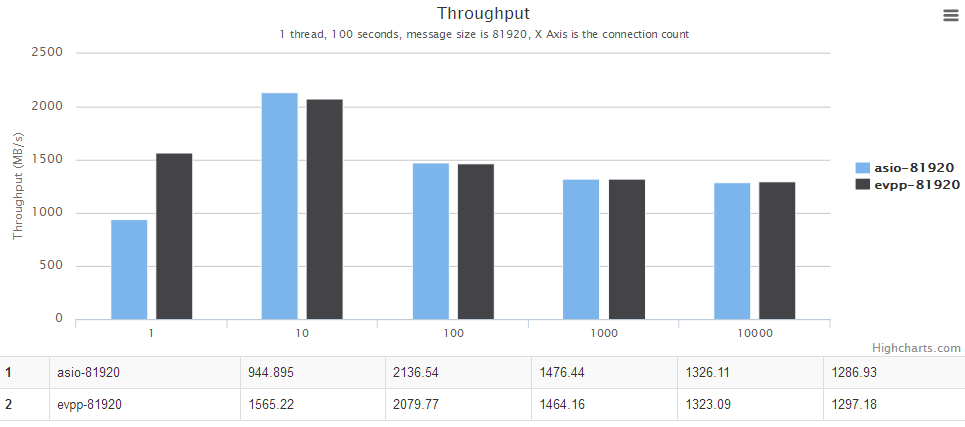
For details, see the chart below, the horizontal axis is the number of concurrent connections. The vertical axis is the throughput, the bigger the better.
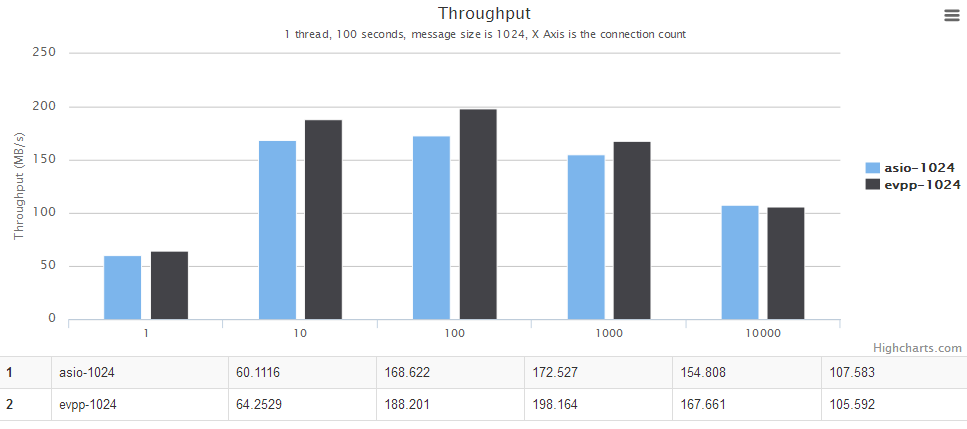
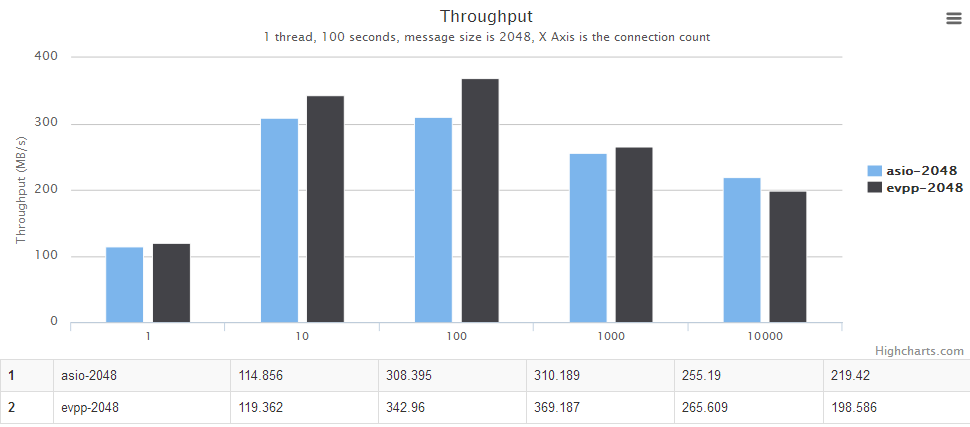
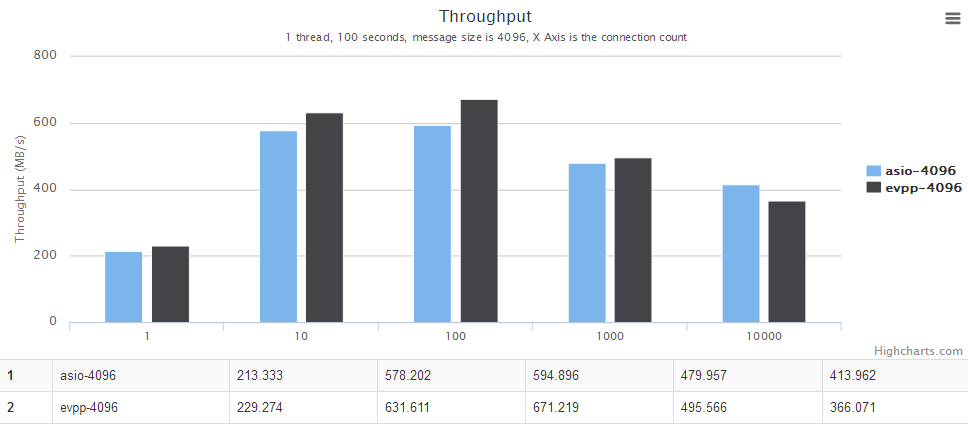
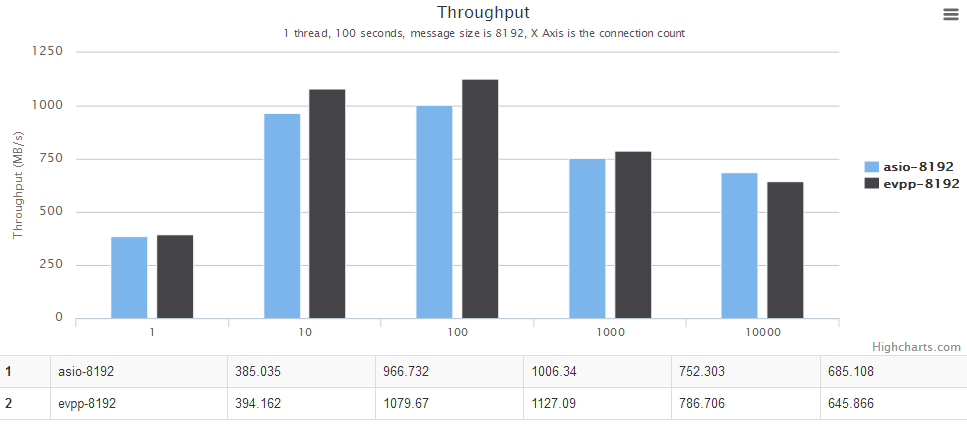
For details, see the chart below. The horizontal axis is the number of threads. The vertical axis is the throughput, the bigger the better.
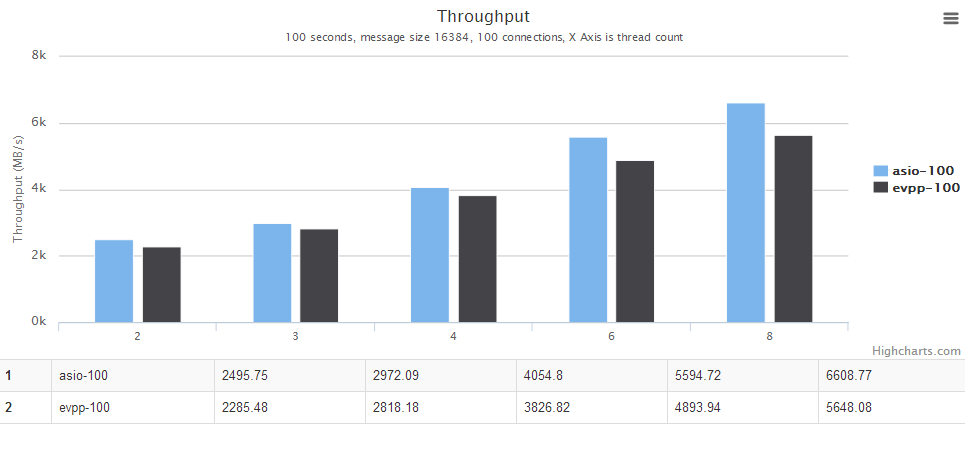
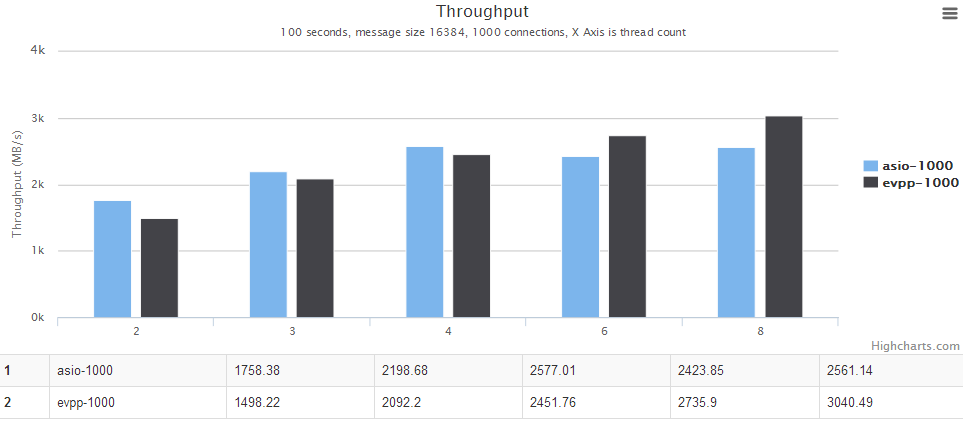
In this ping pong benchmark test, the asio's test code is using a fixed-size buffer to receive and send the data. That can take advantage of asio Proactor model, he has almost no memory allocation. Each time asio only reads fixed size of data and then sent it out, and then use the same BUFFER to do the next read operation.
In the same time evpp is a network library of Reactor model, the receiving data is probably not a fixed size, which involves evpp::Buffer internal memory reallocation problems that lead to excessive memory allocation.
We will do another benchmark test to verify the analysis. Please look forward to it.
The IO Event performance benchmark against Boost.Asio : evpp is higher than asio about 20%~50% in this case
The ping-pong benchmark against Boost.Asio : evpp is higher than asio about 5%~20% in this case
The throughput benchmark against libevent2 : evpp is higher than libevent about 17%~130% in this case
The performance benchmark of queue with std::mutex against boost::lockfree::queue and moodycamel::ConcurrentQueue : moodycamel::ConcurrentQueue is the best, the average is higher than boost::lockfree::queue about 25%~100% and higher than queue with std::mutex about 100%~500%
The throughput benchmark against Boost.Asio : evpp and asio have the similar performance in this case
The throughput benchmark against Boost.Asio(中文) : evpp and asio have the similar performance in this case
The throughput benchmark against muduo(中文) : evpp and muduo have the similar performance in this case
The beautiful chart is rendered by gochart. Thanks for your reading this report. Please feel free to discuss with us for the benchmark test.
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。





