

代码拉取完成,页面将自动刷新
同步操作将从 zieckey/evpp 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
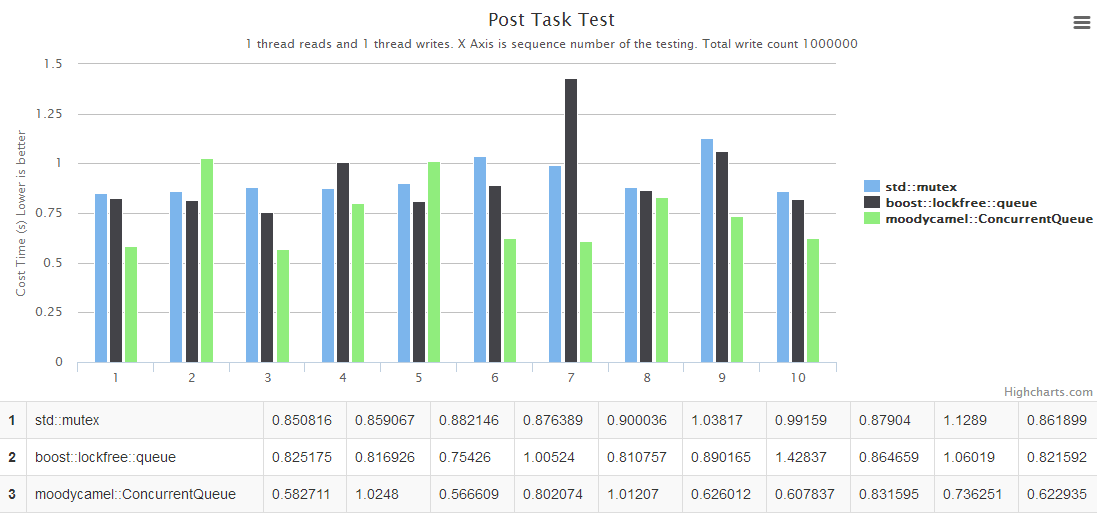
The performance benchmark of queue with std::mutex against boost::lockfree::queue and moodycamel::ConcurrentQueue
中文版:基于evpp的EventLoop实现来对无锁队列做一个性能测试对比
We can use EventLoop::QueueInLoop(...) from evpp to execute a task. In one thread, we can use this method to post a task and make this task to be executed in another thread. This is a typical producer/consumer problem.
We can use a queue to store the task. The producer can put tasks to the queue and the consumer takes tasks from queue to execute. In order to avoid thread-safe problems, we need to use a mutex to lock the queue when we modify it, or we can use lock-free mechanism to share data between threads.
Test code is at here https://github.com/Qihoo360/evpp/blob/master/benchmark/post_task/post_task6.cc. The producers post task into the queue the only one consumer to execute. We can specify the count of producer threads and the total count of the tasks posted by every producer.
The relative code of event_loop.h is bellow:
std::shared_ptr<PipeEventWatcher> watcher_;
#ifdef H_HAVE_BOOST
boost::lockfree::queue<Functor*>* pending_functors_;
#elif defined(H_HAVE_CAMERON314_CONCURRENTQUEUE)
moodycamel::ConcurrentQueue<Functor>* pending_functors_;
#else
std::mutex mutex_;
std::vector<Functor>* pending_functors_; // @Guarded By mutex_
#endif
And the relative code of event_loop.cc is bellow:
void Init() {
watcher_->Watch(std::bind(&EventLoop::DoPendingFunctors, this));
}
void EventLoop::QueueInLoop(const Functor& cb) {
{
#ifdef H_HAVE_BOOST
auto f = new Functor(cb);
while (!pending_functors_->push(f)) {
}
#elif defined(H_HAVE_CAMERON314_CONCURRENTQUEUE)
while (!pending_functors_->enqueue(cb)) {
}
#else
std::lock_guard<std::mutex> lock(mutex_);
pending_functors_->emplace_back(cb);
#endif
}
watcher_->Notify();
}
void EventLoop::DoPendingFunctors() {
#ifdef H_HAVE_BOOST
Functor* f = nullptr;
while (pending_functors_->pop(f)) {
(*f)();
delete f;
}
#elif defined(H_HAVE_CAMERON314_CONCURRENTQUEUE)
Functor f;
while (pending_functors_->try_dequeue(f)) {
f();
--pending_functor_count_;
}
#else
std::vector<Functor> functors;
{
std::lock_guard<std::mutex> lock(mutex_);
notified_.store(false);
pending_functors_->swap(functors);
}
for (size_t i = 0; i < functors.size(); ++i) {
functors[i]();
}
#endif
}
We have done two benchmarks:
boost::lockfree::queue has only a little advantages to queue with std::mutex and moodycamel::ConcurrentQueue's performance is the best.boost::lockfree::queue is better, the average is higher than queue with std::mutex about 75%~150%. moodycamel::ConcurrentQueue is the best, the average is higher than boost::lockfree::queue about 25%~100%, and higher than queue with std::mutex about 100%~500%. The more count of producers, the higher performance of moodycamel::ConcurrentQueue will getSo we suggest to use moodycamel::ConcurrentQueue to exchange datas between threads insdead of queue with std::mutex or boost::lockfree::queue
For more details, see the chart below, the horizontal axis is the count of producer threads. The vertical axis is the executing time in seconds, lower is better.

The IO Event performance benchmark against Boost.Asio : evpp is higher than asio about 20%~50% in this case
The ping-pong benchmark against Boost.Asio : evpp is higher than asio about 5%~20% in this case
The throughput benchmark against libevent2 : evpp is higher than libevent about 17%~130% in this case
The performance benchmark of queue with std::mutex against boost::lockfree::queue and moodycamel::ConcurrentQueue : moodycamel::ConcurrentQueue is the best, the average is higher than boost::lockfree::queue about 25%~100% and higher than queue with std::mutex about 100%~500%
The throughput benchmark against Boost.Asio : evpp and asio have the similar performance in this case
The throughput benchmark against Boost.Asio(中文) : evpp and asio have the similar performance in this case
The throughput benchmark against muduo(中文) : evpp and muduo have the similar performance in this case
The beautiful chart is rendered by gochart. Thanks for your reading this report. Please feel free to discuss with us for the benchmark test.
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。





