

代码拉取完成,页面将自动刷新
同步操作将从 kerlomz/captcha_trainer 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。
基于深度学习的图片验证码的解决方案 - 该项目能够秒杀字符粘连重叠/透视变形/模糊/噪声等各种干扰情况,足以解决市面上绝大多数复杂的验证码场景,目前也被用于其他OCR场景。
该项目基于 TensorFlow 1.14 开发,旨在帮助中小企业或个人用户快速构建图像分类模型并投入生产环境使用,降低技术应用门槛。
面向算法工程师:提供了可拓展的结构支持,允许通过源码灵活方便的添加自己设计的网络结构及其他组件。
面向零基础用户:有需求?但是不会编程?时间就是金钱,学习成本太高我想白嫖。它简直为你而生!
面向需求频繁者:同样的类型的需求一天10个,它的复用程度让您无需一份代码一个需求,一套服务全部搞定。
编译版下载地址: https://github.com/kerlomz/captcha_trainer/releases/
其使用的网络结构主要包含三部分,从下至上依次为:
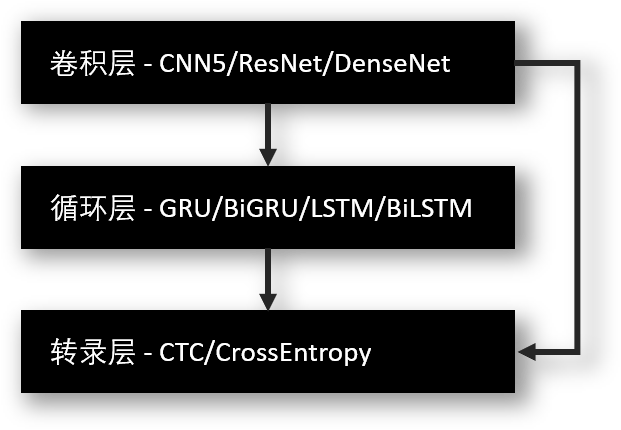
卷积层:从输入图像中提取特征序列;
循环层,预测从卷积层获取的特征序列的标签(真实值)分布;
转录层,把从循环层获取的标签分布通过去重整合等操作转换成最终的识别结果;
为每个图像分类任务创建一个独立的项目,每个项目拥有完全独立的管理空间,方便多任务切换和管理。全程无需修改一行代码,根据模板生成模型配置,生成的配置文件可直接用模型部署服务。
本项目对应的部署服务支持同时部署多套模型,模型支持热拔插,版本迭代等,业务层可拓展颜色提取,算术运算等常见的验证码解决方案。详情可以移步:https://github.com/kerlomz/captcha_platform
# - requirement.txt - GPU: tensorflow-gpu, CPU: tensorflow
# - If you use the GPU version, you need to install some additional applications.
# MemoryUsage: 显存占用率,推荐0.6-0.8之间
System:
MemoryUsage: {MemoryUsage}
Version: 2
# CNNNetwork: [CNN5, ResNet50, DenseNet]
# RecurrentNetwork: [CuDNNBiLSTM, CuDNNLSTM, CuDNNGRU, BiLSTM, LSTM, GRU, BiGRU, NoRecurrent]
# - 推荐配置为 不定长问题:CNN5+GRU ,定长:CNN5/DenseNet/ResNet50
# UnitsNum: RNN层的单元数 [16, 64, 128, 256, 512]
# - 神经网络在隐层中使用大量神经元,就是做升维,将纠缠在一起的特征或概念分开。
# Optimizer: 优化器算法 [AdaBound, Adam, Momentum]
# OutputLayer: [LossFunction, Decoder]
# - LossFunction: 损失函数 [CTC, CrossEntropy]
# - Decoder: 解码器 [CTC, CrossEntropy]
NeuralNet:
CNNNetwork: {CNNNetwork}
RecurrentNetwork: {RecurrentNetwork}
UnitsNum: {UnitsNum}
Optimizer: {Optimizer}
OutputLayer:
LossFunction: {LossFunction}
Decoder: {Decoder}
# ModelName: 模型名/项目名,同时也对应编译后的pb模型文件名
# ModelField: 模型处理的数据类型,目前只支持图像 [Image, Text]
# ModelScene: 模型处理的场景类型,目前只支持分类场景 [Classification]
# - 目前只支持 “图像分类” 这一种场景.
Model:
ModelName: {ModelName}
ModelField: {ModelField}
ModelScene: {ModelScene}
# FieldParam 分为 Image, Text 两种,不同数据类型时可配置的参数不同,目前只提供 Image 一种。
# ModelField 为 Image 时:
# - Category: 提供默认的内置解决方案:
# -- [ALPHANUMERIC(含大小写英文数字), ALPHANUMERIC_LOWER(小写英文数字),
# -- ALPHANUMERIC_UPPER(大写英文数字),NUMERIC(数字), ALPHABET_LOWER(小写字母),
# -- ALPHABET_UPPER(大写字母), ALPHABET(大小写字母),
# -- ALPHANUMERIC_CHS_3500_LOWER(小写字母数字混合中文常用3500)]
# - 或者可以自定义指定分类集如下(中文亦可):
# -- ['Cat', 'Lion', 'Tiger', 'Fish', 'BigCat']
# - Resize: 重置尺寸,对应网络的输入: [ImageWidth, ImageHeight/-1, ImageChannel]
# - ImageChannel: 图像通道,3为原图,1为灰度 [1, 3]
# - 为了配合部署服务根据图片尺寸自动选择对应的模型,由此诞生以下参数(ImageWidth,ImageHeight):
# -- ImageWidth: 图片宽度.
# -- ImageHeight: 图片高度.
# - MaxLabelNum: 该参数在使用CTC损失函数时将被忽略,仅用于使用交叉熵作为损失函数/标签数固定时使用
# ModelField 为 Text 时:
# - 该类型暂时不支持
FieldParam:
Category: {Category}
Resize: {Resize}
ImageChannel: {ImageChannel}
ImageWidth: {ImageWidth}
ImageHeight: {ImageHeight}
MaxLabelNum: {MaxLabelNum}
OutputSplit: {OutputSplit}
# 该配置应用于数据源的标签获取.
# LabelFrom: 标签来源,目前只支持 从文件名提取 [FileName, XML, LMDB]
# ExtractRegex: 正则提取规则,对应于 从文件名提取 方案 FileName:
# - 默认匹配形如 apple_20181010121212.jpg 的文件.
# - 默认正则为 .*?(?=_.*\.)
# LabelSplit: 该规则仅用于 从文件名提取 方案:
# - 文件名中的分割符形如: cat&big cat&lion_20181010121212.png,那么分隔符为 &
# - The Default is null.
Label:
LabelFrom: {LabelFrom}
ExtractRegex: {ExtractRegex}
LabelSplit: {LabelSplit}
# DatasetPath: [Training/Validation], 打包为TFRecords格式的训练集/验证集的本地绝对路径。
# SourcePath: [Training/Validation], 未打包的训练集/验证集源文件夹的本地绝对路径。
# ValidationSetNum: 验证集数目,仅当未配置验证集源文件夹时用于系统随机抽样用作验证集使用。
# - 该选项用于懒人训练模式,当样本极度不均衡时建议手动设定合理的验证集。
# SavedSteps: 当 Session.run() 被执行一次为一步(1.x版本),保存训练过程的步数,默认为100。
# ValidationSteps: 用于计算准确率,验证模型的步数,默认为每500步验证一次。
# EndAcc: 结束训练的条件之准确率 [EndAcc*100]% 到达该条件时结束任务并编译模型。
# EndCost: 结束训练的条件之Cost值 EndCost 到达该条件时结束任务并编译模型。
# EndEpochs: 结束训练的条件之样本训练轮数 Epoch 到达该条件时结束任务并编译模型。
# BatchSize: 批次大小,每一步用于训练的样本数量,不宜过大或过小,建议64。
# ValidationBatchSize: 验证集批次大小,每个验证准确率步时,用于验证的样本数量。
# LearningRate: 学习率 [0.1, 0.01, 0.001, 0.0001] fine-tuning 时选用较小的学习率。
Trains:
DatasetPath:
Training: {DatasetTrainsPath}
Validation: {DatasetValidationPath}
SourcePath:
Training: {SourceTrainPath}
Validation: {SourceValidationPath}
ValidationSetNum: {ValidationSetNum}
SavedSteps: {SavedSteps}
ValidationSteps: {ValidationSteps}
EndAcc: {EndAcc}
EndCost: {EndCost}
EndEpochs: {EndEpochs}
BatchSize: {BatchSize}
ValidationBatchSize: {ValidationBatchSize}
LearningRate: {LearningRate}
# 以下为数据增广的配置
# Binaryzation: 该参数为 list 类型,包含二值化的上界和下界,值为 int 类型,参数为 -1 表示未启用。
# MedianBlur: 该参数为 int 类型,参数为 -1 表示未启用。
# GaussianBlur: 该参数为 int 类型,参数为 -1 表示未启用。
# EqualizeHist: 该参数为 bool 类型。
# Laplace: 该参数为 bool 类型。
# WarpPerspective: 该参数为 bool 类型。
# Rotate: 该参数为大于 0 的 int 类型,参数为 -1 表示未启用。
# PepperNoise: 该参数为小于 1 的 float 类型,参数为 -1 表示未启用。
# Brightness: 该参数为 bool 类型。
# Saturation: 该参数为 bool 类型。
# Hue: 该参数为 bool 类型。
# Gamma: 该参数为 bool 类型。
# ChannelSwap: 该参数为 bool 类型。
# RandomBlank: 该参数为大于 0 的 int 类型,参数为 -1 表示未启用。
# RandomTransition: 该参数为大于 0 的 int 类型,参数为 -1 表示未启用。
DataAugmentation:
Binaryzation: {DA_Binaryzation}
MedianBlur: {DA_MedianBlur}
GaussianBlur: {DA_GaussianBlur}
EqualizeHist: {DA_EqualizeHist}
Laplace: {DA_Laplace}
WarpPerspective: {DA_WarpPerspective}
Rotate: {DA_Rotate}
PepperNoise: {DA_PepperNoise}
Brightness: {DA_Brightness}
Saturation: {DA_Saturation}
Hue: {DA_Hue}
Gamma: {DA_Gamma}
ChannelSwap: {DA_ChannelSwap}
RandomBlank: {DA_RandomBlank}
RandomTransition: {DA_RandomTransition}
# 以下为预处理的配置
# Binaryzation: 该参数为 list 类型,包含二值化的上界和下界,值为 int 类型,参数为 -1 表示未启用。
# ReplaceTransparent: 使用白色替换透明背景
# HorizontalStitching: 水平拆分拼接,适用于上下分层
# ConcatFrames: 根据帧索引列表水平合并帧
# BlendFrames: 根据帧索引列表融合帧内容
Pretreatment:
Binaryzation: {Pre_Binaryzation}
ReplaceTransparent: {Pre_ReplaceTransparent}
HorizontalStitching: {Pre_HorizontalStitching}
ConcatFrames: {Pre_ConcatFrames}
BlendFrames: {Pre_BlendFrames}
注意:如果你使用笔者编译好的版本,只需更新显卡驱动至最新,可以无视2.1、2.2的环境安装步骤。
如果你准备使用GPU训练,请先更新显卡驱动并安装CUDA和cuDNN,可以了解下官方测试过的编译版本对应: https://www.tensorflow.org/install/install_sources#tested_source_configurations
Github上可以下载到第三方编译好的TensorFlow的WHL安装包:
CUDA下载地址:https://developer.nvidia.com/cuda-downloads
cuDNN下载地址:https://developer.nvidia.com/rdp/form/cudnn-download-survey (需要注册账号)
笔者使用的版本为:CUDA10 + cuDNN7.6 + TensorFlow 1.14,此种组合可使用pip安装无需下载第三方编译的whl安装包。
安装Python 3.7 环境(包含pip),可用conda替换。
安装虚拟环境 virtualenv pip3 install virtualenv
为该项目创建独立的虚拟环境:
virtualenv -p /usr/bin/python3 venv # venv is the name of the virtual environment.
cd venv/ # venv is the name of the virtual environment.
source bin/activate # to activate the current virtual environment.
cd captcha_trainer # captcha_trainer is the project path.
安装本项目的依赖列表:pip install -r requirements.txt
建议开发者们使用 PyCharm 作为Python IDE
笔者这个项目的初衷其实是爬虫遭遇各种验证码,验证码无处不在且需求堆积如山,由此,懒诞生了创造力。
图像分类问题,以验证码为例,用深度学习来解决无非就是训练标注样本。那么样本从何而来?这就是建模流程的第一步。
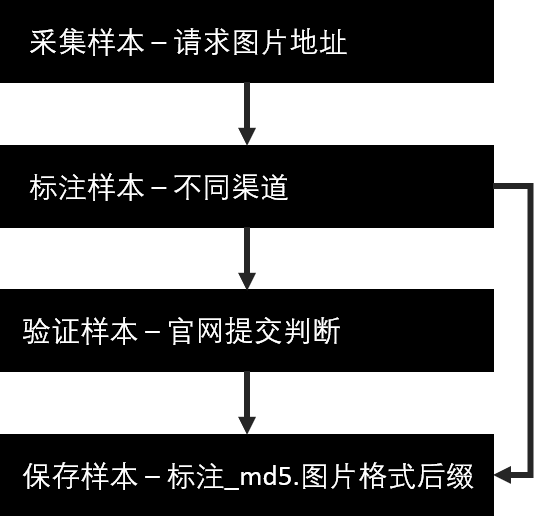
采集样本: 一般可以通过抓包得到对方网站的接口请求及参数,通过构造请求采集样本。
标注样本: 标注渠道是有一定讲究的,一般采用多个渠道组合,因为现在大多是机器识别,导致保存过滤下来的正确样本可能存在特征缺失,举个例子,这个渠道把所有的b都识别成a,为了避免这种情况建议通过多个渠道组合采集样本,以此保证图片特征的覆盖率。
验证样本:如何提交验证?比如如何从登录页面中获取样本,其实大多时候后端设计都会为了避免过多恶意的数据库访问而先验证验证码的准确性,例如可以提交明显错误的信息,输入不存在的用户名,将对方网站返回的“用户名不存在”作为验证码正确性的判断条件,当验证码错误时如返回“验证码错误”,则验证样本的流程便成立了。
本框架喂数据只接收从TFRecords中读取,也就是样本需要先打包成TFRecords文件格式,样本打包的源目录路径关联的参数为:
SourcePath:
Training: {SourceTrainPath}
Validation: {SourceValidationPath}
打包完的TFRecords文件的路径关联的参数为:
DatasetPath:
Training: {DatasetTrainsPath}
Validation: {DatasetValidationPath}
项目配置好之后 ,可通过两种方法进行打包
make_dataset.py 打包
运行python make_dataset.py 项目名 方式打包,则需要加启动参数指定训练项目,请确保 projects/项目名 路径下存放各个项目的 model.yaml 配置文件。
app.py训练:
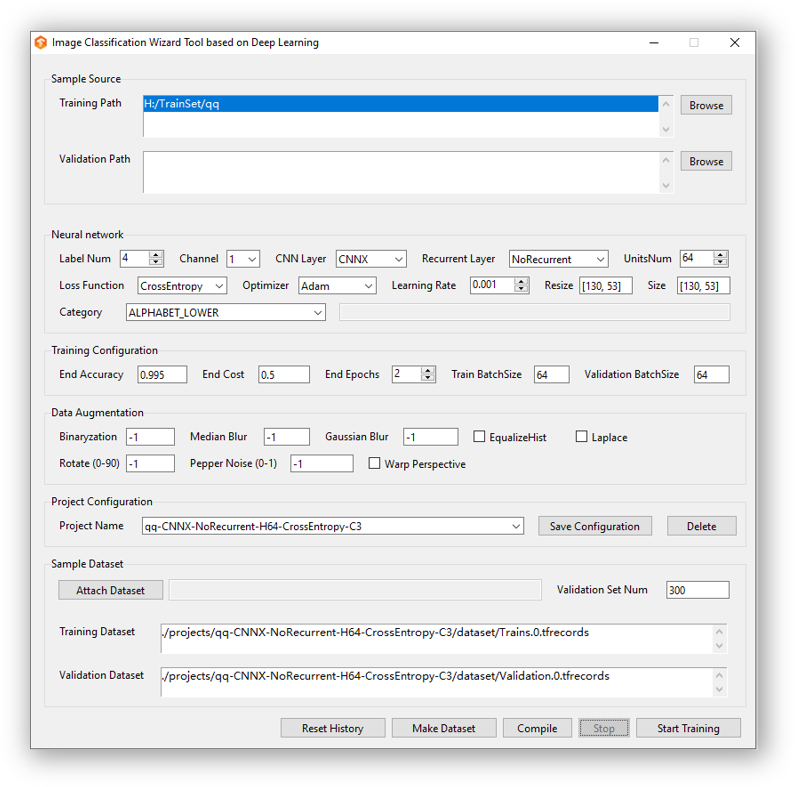
在界面中选择欲使用的网络结构,输入项目名并[回车]或者点击空白处 创建一个新项目 或者 选择一个已有的项目 ,通过 [Browse] 选择训练集路径 后,点击 [Make Dataset] 开始打包 ,中途若终止进程文件将损坏,需要手动至项目路径中删除其未打包完成的样本集,[Validation Path] 可以不选,如若不选,系统将根据 [Validation Set Num] 配置的参数自动分配该数量的验证集,
注意:手动配置训练集的时候请保证验证集的随机性以及特征覆盖率,如若不明笔者所语,请勿手动配置
使用app.py运行的界面化配置生成器在选择样本源的时候会自动进行基本的配置如:[Resize],[Size],[Label Num] 等。至于 [Label Num] 只在使用CrossEntropy为损失函数时有效。
因为网络为多标签而设计,卷积层的输出 outputs 经过了以下变换:
Reshape([label_num, int(outputs_shape[1] / label_num)])
为了保证运算 int(outputs_shape[1] / label_num) 能够取得正整数,也意味着他们之间存在某种关系,对于CNN5+Cross Entropy的网络结构,Conv2D层的步长皆为1,那么需要保证以下关系成立:
$$ mod(\frac{输入宽度\times输入高度\times输出层参数}{池化步长^{池化层数}\times标签数})= 0 $$
所以有时候需要Resize网络输入的Shape
| 网络 | 池化步长^池化层数 | 输出层参数 |
|---|---|---|
| CNN5 | 16 | 64 |
| CNNX | 8 | 64 |
| ResNet50 | 16 | 1024 |
| DenseNet | 32 | 2048 |
例如使用CNN5+CrossEntropy组合,则输入宽度与输入高度需要满足: $$ mod(\frac{输入宽度\times输入高度\times64}{16\times标签数})= 0 $$ 同理如果CNN5+RNN+CTC,卷积层之后的输出经过以下变换:
Reshape([-1, outputs_shape[2] * outputs_shape[3]])
原输出(batch_size, outputs_shape[1], outputs_shape[2], outputs_shape[3]),RNN层的输入输出要求为(batch, timesteps, num_classes),为了接入RNN经过以上操作,那么又引出一个Time Step的概念,所以timesteps的值也是 outputs_shape[1],而CTC Loss要求的输入为 [batch_size, frames, num_labels],若是 timesteps 小于标签数则无法计算损失,也就无法找损失函数中找到极小值,梯度何以下降。timesteps 最合理的值一般是标签数的2倍,为了达到目的,也可以通过Resize网络输入的Shape解决,一般情况timesteps直接关联于图片宽度。
正则匹配,请各位采集样本的时候,尽量和我给的示例保持一致吧,正则问题请谷歌,如果是为1111.jpg这种命名的话,这里提供了一个批量转换的代码:
import re
import os
import hashlib
# 训练集路径
root = r"D:\TrainSet\***"
all_files = os.listdir(root)
for file in all_files:
old_path = os.path.join(root, file)
# 已被修改过忽略
if len(file.split(".")[0]) > 32:
continue
# 采用标注_文件md5码.图片后缀 进行命名
with open(old_path, "rb") as f:
_id = hashlib.md5(f.read()).hexdigest()
new_path = os.path.join(root, file.replace(".", "_{}.".format(_id)))
# 重复标签的时候会出现形如:abcd (1).jpg 这种形式的文件名
new_path = re.sub(" \(\d+\)", "", new_path)
print(new_path)
os.rename(old_path, new_path)
trains.py训练:
如果单独调用 python trains.py 项目名 方式训练,则需要加启动参数指定训练项目,请确保 projects/项目名 路径下存放各个项目的 model.yaml 配置文件。
app.py训练:
在界面中配置好参数后,点击 [Start Training] 开始训练,中途若需终止训练可点击 [Stop] 停止,若是未达到结束条件而终止任务,可以手动点击 [Compile] 编译。
|-- fc // 全连接层
| |-- cnn.py // 卷积层的全连接
| `-- rnn.py // 循环层的全连接
|-- logs // Tensor Board 日志
|-- network // 神经网络实现
| | |-- CNN.py // CNN5/CNNX
| | |-- DenseNet.py // DenseNet
| | |-- GRU.py // GRU/BiBRU/GRUcuDNN
| | |-- LSTM.py // LSTM/BiLSTM/LSTMcuDNN
| | |-- ResNet.py // ResNet50
| | `-- utils.py // 各种网络 block 的实现
|-- optimizer // 优化器
| | `-- AdaBound.py // AdaBound 优化算法实现
|-- projects // 项目存放路径
| `-- demo // 项目名
| |-- dataset // 数据集存放
| |-- model // 训练过程记录存放
| `-- out // 模型编译输出
| |-- graph // 存放编译pb模型
| `-- model // 存放编译yaml配置
|-- resource // 资源:图标,README 所需图片
|-- tools
| `-- package.py // PyInstaller编译脚本
|-- utils
| |-- data.py // 数据加载工具类
| `-- sparse.py // 稀疏矩阵处理工具类
|-- app.py // GUI配置生成器
|-- app.spec // PyInstaller编译配置文件
|-- category.py // 内置类别模块
|-- config.py // 配置实体模块
|-- constants.py // 各种枚举类
|-- core.py // 神经网络模块
|-- decoder.py // 解码器
|-- encoder.py // 编码器
|-- exception.py // 异常模块
|-- loss.py // 损失函数
|-- make_dataset.py // 样本集打包
|-- model.template // 配置模板
|-- predict_testing.py // 预测测试
|-- pretreatment.py // 预处理
|-- requirements.txt // 项目依赖
|-- trains.py // 训练模块
`-- validation.py // 验证模块
如何使用CPU训练:
本项目默认安装TensorFlow-GPU版,建议使用GPU进行训练,如需换用CPU训练请替换 requirements.txt 文件中的tensorflow-gpu==1.14.0 为tensorflow==1.14.0,其他无需改动。
参数修改:
切记,[ModelName] 是绑定一个模型的唯一标志,如果修改了训练参数如:[Resize],[Category],[CNNNetwork],[RecurrentNetwork],[UnitsNum] 这类影响计算图的参数,需要删除model路径下的旧文件,重新训练,或者使用新的 [ModelName] 重新训练,否则默认作为断点续练。
在可视化版本中,[Neural Net] 组中的配置,除了学习率 [Learning Rate] 和图片尺寸 [Size] 设置以外,任何改动都需要先 [Reset History]

问题一: 有人问,验证码是什么,简单送上一幅图,验证码早已不是Tesseract能解决的时代了,为什么选择验证码作为图像分类的入门,其一因为随处可见,对于深度学习样本不可或缺,验证码的采集难度及成本低。其二,现在的验证码越来越难也越来越具备研究价值,因为它本为安全而生,各种人为的干扰甚至于机器学习对抗等等,也在不断促进图像识别的发展。
问题二: 部署识别也需要GPU吗?我的答案是,完全没必要。理想中是用GPU训练,使用CPU部署识别服务,部署如果也需要这么高的成本,那还有什么现实意义和应用场景呢,实测CNN5网络,我的i7-9700k大约1-15ms之间 (图片尺寸60x60-200x200)。
此项目以研究学习为目的,禁止用于非法用途,本项目永久开源,笔者将持续维护此项目,并逐步扩展其成为一个完善的深度学习框架。
如有需要欢迎进群交流,落魄算法,在线答疑:
图像识别技术:857149419
数据矿工:778910502
思知人工智能:90780053
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。





